Sopra Steria undertook a project to study the impact of COVID-19 on frontline workers by analyzing the posts that these frontline workers put on social media. The reason for the same was to analyze the intangible impact – psychological, physical and material that this crisis was having on these warriors. For this purpose, a novel dataset consisting of posts from various frontline workers (doctors, nurses, cashiers, fast food workers, agricultural workers, truck drivers etc.) was extracted from the social media platform -Reddit.
After understanding the general emotions of these workers through their posts, a classifier was developed to detect the users who were at enhanced risk to severe mental distress (such as depression or anxiety leading to suicidal ideation), using models pre-trained on social media posts.
Different models were tested for this purpose with different features (statistical, syntactic, word and sentence embeddings), and their overall accuracy was compared and contrasted. These trends were visualized using Tableau, leading to interesting conclusions.
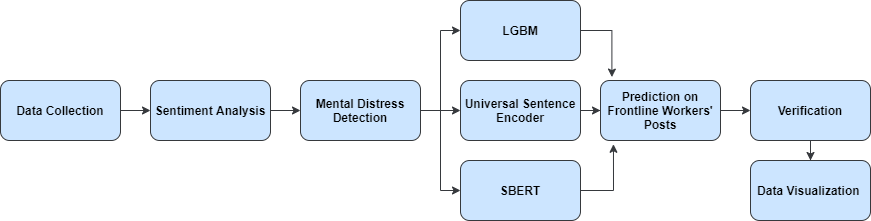
DATA COLLECTION
For this research, posts and comments were extracted from Reddit using the Pushshift.io API and communities (“subreddits”) meant for frontline workers were targeted. This platform was selected since it allows its users to generate content anonymously, with only a username for identity. Only posts related to coronavirus were extracted, using a keyword-specific search like coronavirus, covid19, corona, Wuhan, china flu, covid, mask, social distancing, and pandemic. Related posts between December 1st 2019 and May 24th 2020 were obtained. A new novel dataset with more than 10,000 entries from frontline workers was created.
SENTIMENT ANALYSIS
For this analysis, the text body as well as the title of the posts were used, and the overall sentiment was extracted using VADER and TextBlob. On the text posts, VADER displayed the overall sentiment - positive, negative, or neutral – for the entire collection of sentences. There is a fourth value, ‘compound’ which gives the overall sentiment of the text.
With TextBlob, the polarity and subjectivity of the text posts was found, with polarity ranging from -1 to +1, and subjectivity between 0 and 1. Polarity is related to emotions; a high polarity score implies that the text is positive while a low polarity implies negativity. In case of subjectivity, a high score indicates that the text is subjective i.e. opinionated. A low subjectivity score indicates that the text is more objective, or factual.
MENTAL DISTRESS DETECTION
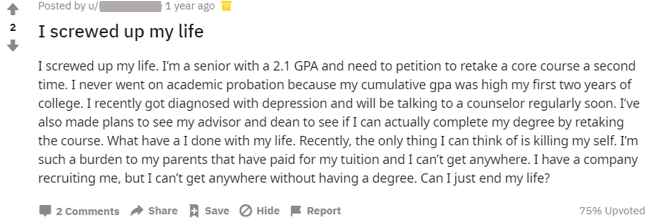
A balanced dataset from Reddit comprising of more than 100,000 posts, prelabelled as suffering from extreme mental distress or not possessing such tendencies was created.
This dataset was created by extracting posts from r/SuicideWatch, a community where users generally post about their suicidal thoughts. Non-suicidal posts, i.e. posts with no suicidal tendencies, were extracted from other popular subreddits, r/books, r/jokes, r/legaladvice, r/casualconversation, and r/college, to create a roughly balanced dataset.
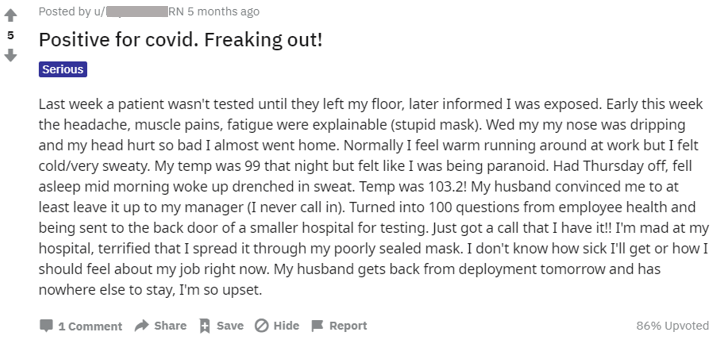
Using this dataset, models were created to detect differences in how users suffering from severe mental health issues may have different posting patterns and habits compared to others. Example of a mentally stressed post from Reddit
- LGBM (Light Gradient Boosted Machine)
.png?sfvrsn=aef61fdc_1)
For building the supervised learning model, apart from the features obtained from the sentiment analysis, statistical, syntactic, and categorical features were also extracted.
Statistical: The number of words, characters, sentences, average sentence length, stop-words, special characters, alphabets, and numbers were obtained for both the title and the text following it. Additionally, the total number of derogatory words was counted.
Metadata: The data extracted about the post were used, such as the score, number of comments, and the date and time of publishing.
Syntactic: Parts-of-Speech [POS] tagging was done on the text body to capture grammatical variations. The total number of these tags were counted.
Categorical: The text is classified according to different categories such as ‘family’, ‘health’, ‘death’, ‘disgust’, and ‘joy’, and the differences between mentally stressed and non-mentally stressed posts are noted, using Empath.
It was observed that these features, along with the TF-IDF scores of the text posts, gave the best results with LGBM, with an accuracy of 96.35%. This was then used to detect the mental health tendencies of the frontline workers, based on their text posts. A binary classification was used, with 1 indicating low mental health and higher suicidal tendencies, and 0 indicating stable mental health.
- USE (Universal Sentence Encoder)
The body of the prelabelled mental distress dataset submissions was encoded to output a 512-dimensional vector using the Universal Sentence Encoder. This was then inputted into a neural network and achieved an accuracy of 97.12% with 100 epochs.
To improve upon the model, both the title and text were considered for prediction. However, this model achieved a lower accuracy of 92.68%.
- SBERT (Sentence Bi-directional Encoder Representations from Transformers)
The title as well as the text body were embedded by concatenating the two together, then the 768-dimensional vector was obtained using SBERT. An accuracy of 98.6% was achieved on the suicidal ideation dataset and was used to predict the mental stability of users in frontline worker communities based on their text posts.
VERIFICATION WITH MISCLASSIFIED POSTS
Following the prediction with LGBM (Light Gradient Boosted Machine), 45 misclassified posts were manually identified. Of these 45, 28 were wrongly predicted to exhibit signs of mental illness. These misclassified posts were compared with predictions of the same posts from the other models, to gain a better understanding as to which one works best.
Despite having the best accuracy among all the models, the predictions using SBERT embeddings with the title and text weren’t as accurate as the other two, correctly classifying 35 of the 45 posts, indicating overfitting. To cure this more data is being procured and also the same is being tried using different validation techniques such as k-fold or cross-validation.
INSIGHTS FROM VISUALIZATION
Using Tableau, and the initial predictions on frontline posts using the supervised LGBM model, visualisations were obtained from which insights could be drawn.
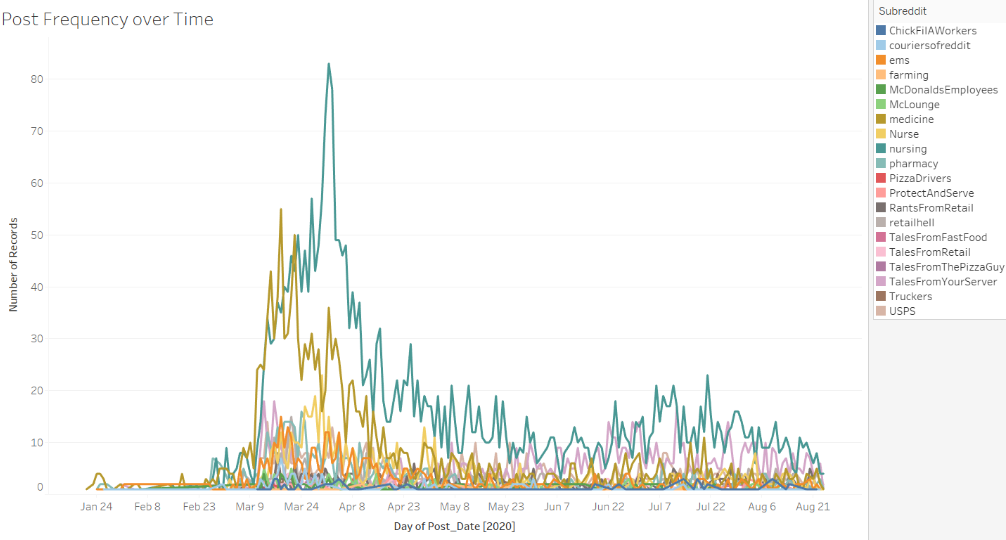
- This explores how the number of posts related to COVID-19 varied with time. The earliest post in the chosen subreddits occurred on January 21st, which was a query about the coronavirus.
The number of related posts increased as awareness about the novel coronavirus did. The subreddit on nursing overall has the greatest number of posts with keywords related to coronavirus. All subreddits saw the frequency sharply increase between the months of March and April – coinciding with WHO declaring the outbreak to be a pandemic. This was also the most chaotic period, with countries enforcing lockdowns and frontline workers being unsure of how to proceed.
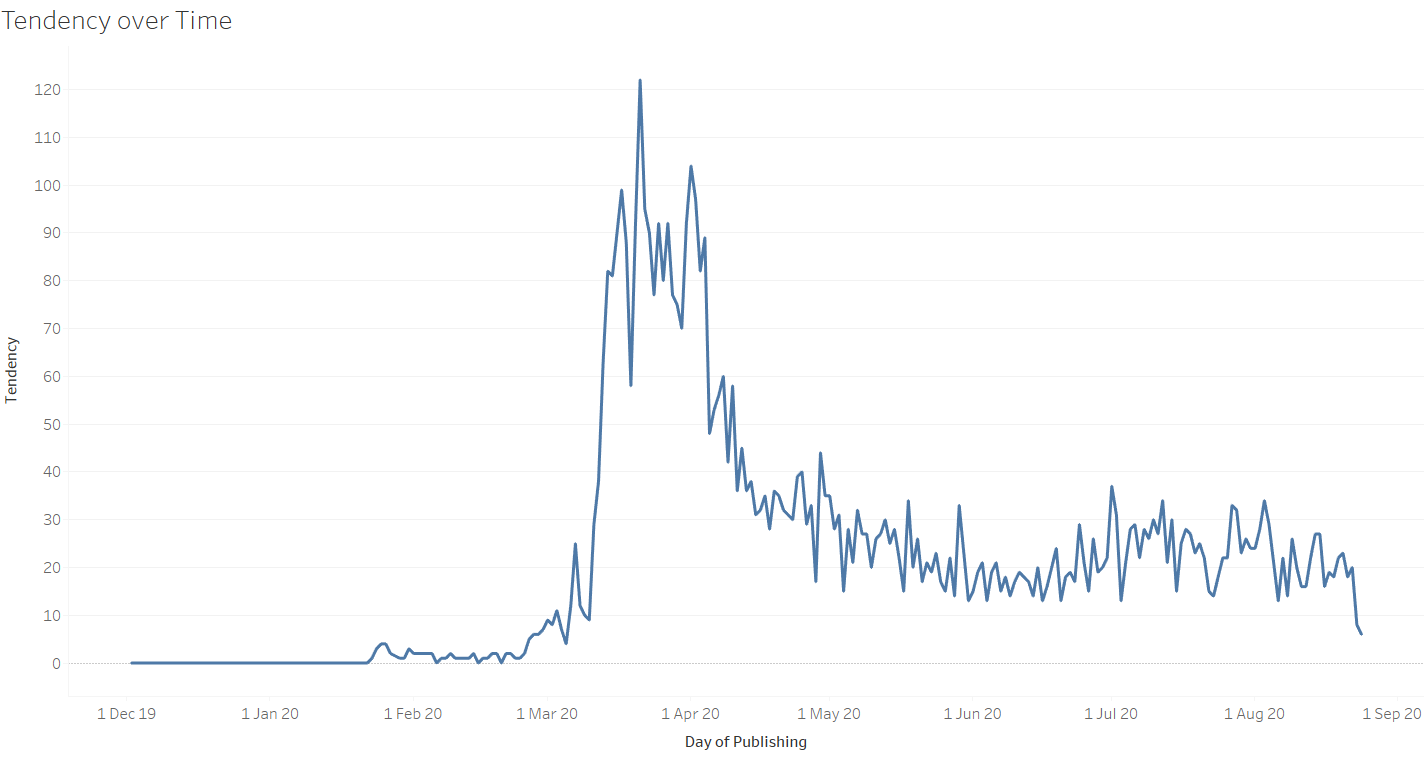
This graph outlines the number of posts that were predicted to exhibit signs of extreme mental stress. Similar to the previous visualization, the numbers peaked between the months of March and April.
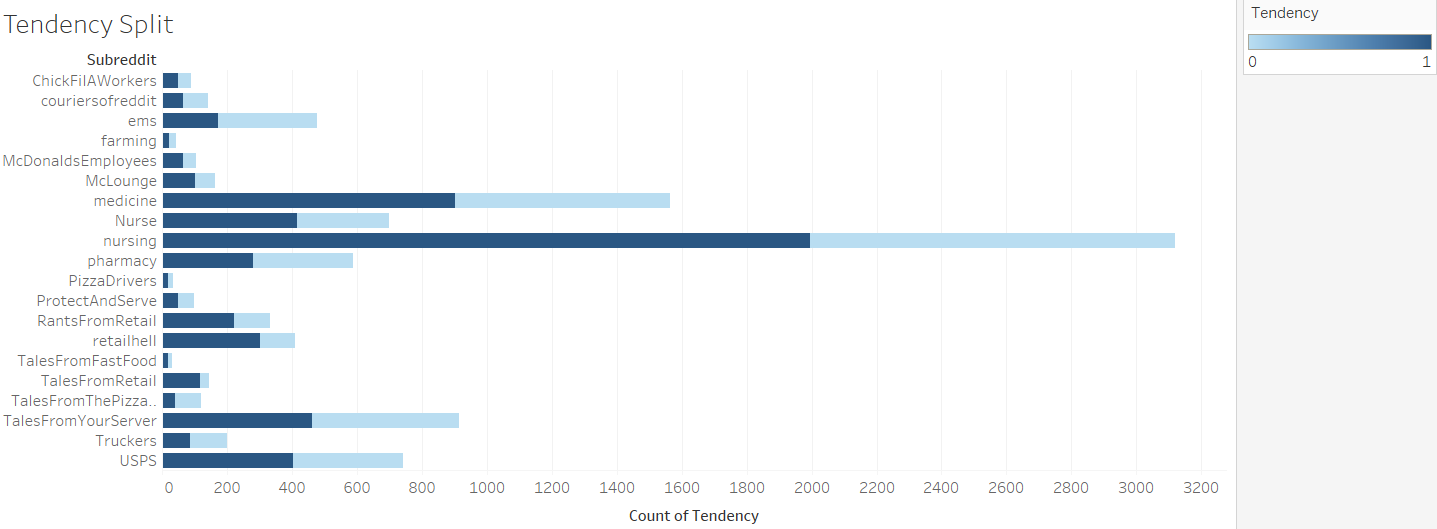
This shows the number of posts made in a particular subreddit, and the proportion of those posts which were classified as showing high levels of mental stress. The highest number of posts were in the subreddit for nursing and more than half of those posts related to COVID-19 exhibit signs of mental distress.
Using these techniques, the inherent and hidden impact of the crisis on the frontline and essential workers can be identified and alerts can be raised so that any further damage can be prevented.
CONTRIBUTORS:
Snigdha Ramkumar | Intern Sopra Steria | Human-Centred Data Science | UX Enthusiast
Aakash Yadav | Sopra Steria | NLP | Deep Learning Enthusiast